AWS東京リージョンに来たAurora with PostgreSQLで遊んでみました
過去最多の13メダル!日本選手団お疲れ様&おめでとう!ひゃっはーー!イエス・ジャパン!
・・・すみません、取り乱しました。
平昌オリンピックが終わってみれば、なんと長野オリンピックを超えるメダル数。凄い。
ヾ(✿❛◡❛)ノ そだねー
今週はパラリンピック!
選手の肉体と最新鋭の機械が融合して対決するのも、また違った迫力でドキドキしますね。
ガンバレ日本!
—-
閑話休題。
今回はデータベース、しかも東京リージョンでリリースしたての Amazon Aurora with PostgreSQL で遊んでみました。
そもそも、Auroraとは?
Amazon Web Services (AWS) が提供しているデータベースサービスには2通りあります。
1.従来型のデータベースをそのままに管理や障害体制を強化した「Amazon RDS」
2.よりスケーラブルに高可用性も徹底してカスタマイズされた「Amazon Aurora(オーロラ)」
Auroraの特徴として、データベースというコンポーネントを「クエリを解釈して応答するフロントエンド層」「キャッシュ層(KVS)」「ストレージ層」に分離してそれぞれがスケーラブルに動作する点が違います。
従来であれば「クエリ解釈+キャッシュ+ストレージ」を1セットにしてマスターやスレーブを構成するのが通例ですが、これはマスターへの変更はスレーブに対してトランザクション(変更履歴)のレプリケーションを行う事でスレーブ側のストレージに反映させるという二重のI/Oがある。
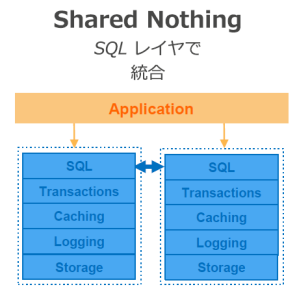
典型的なDBレプリケーションで多いのは、ネットワークを通じてトランザクションを送ってローカルのストレージに反映する構成でしょうか。
しかしAuroraでは、それぞれが分離しておりマスターと各スレーブで“ストレージを共有”している。もちろんストレージはクラスタリングされている。
マスターが変更をストレージに保存したらスレーブにトランザクションを転送する必要も無く、スレーブでも即読めるのである。
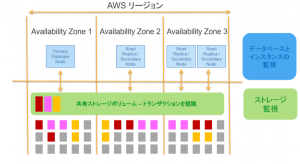
共有されたストレージ側にトランザクション機能がある事に注目。SQL計算ノードとは切り離されている。
スレーブはホットスタンバイしているわけではなく、読み取り専用として参照がいつでもできる「リードレプリカ」です。
このリードレプリカを最大15個まで、ボタンぽちぽちで増やせれる。
キャッシュに使われているKVSも6多重にクラスタリングされていてリードレプリカへの貢献が大きい。
参照系のみリードレプリカ用のエンドポイントを利用できるようにアプリケーション構成を変更できるならその恩恵を十二分に受けれる。
お値段
みんな気になるお値段。2018年3月現在で東京リージョンのAurora with PostgreSQLを利用する場合。
・インスタンス利用料:「db.r4.large」タイプを使う場合
0.35 USD (1インスタンスごと、1時間単位)
マスターとリードレプリカノードの区別はありません。インスタンスタイプの表記や構成はRDSと同じですが価格は違います。
・ストレージ利用料
0.12 USD (1GBごと、月単位)
0.24 USD (100万件のI/Oリクエスト単位)
・そのほか
同じリージョン内であればデータ転送料はかかりません。
別リージョンのEC2やインターネット越しにアクセスする場合は別途料金がかかるのはRDSと同じです。
ちなみに最初のインターネット方向へのアウトバンドで1GBまでは0.00USDなので、簡単なテスト位なら多分超えないかと。
※価格変動するので最新は公式ページでご確認ください。
今回の構成
今回はインスタンスタイプは最小の「db.r4.large」を選択し、実務も考慮してマスターがダウンした時のフェイルオーバーを体験したいのでマルチAZ構成にします。この場合は少なくとも2インスタンス分の起動が必要です。
最小といっても「2vCPU、メモリ15GB」x「2台」もあるので今回のベンチではオーバースペックなくらいです。
これで1時間だけ借りて少し試す程度なら「1.06 USD」(120円弱)となります。
缶コーヒー1本未満のお値段で素敵な環境が手に入るのは良い時代になったものです。
さっそくレッツトライ!
クラスターを作るよ
AuroraはRDSの中の1つ、「クラスター」のメニューから作成できます。
基本はウィザードに沿ってぽちぽちするだけです。
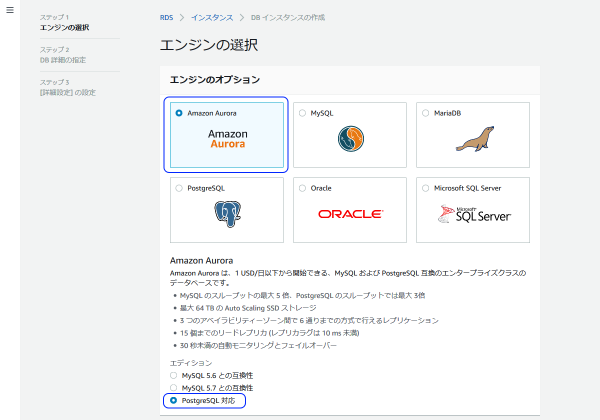
東京リージョンでAurora選ぶと、下部でPostgreSQLが選べるようになってます。これを選びます。
引き続き構成を決めていきます。
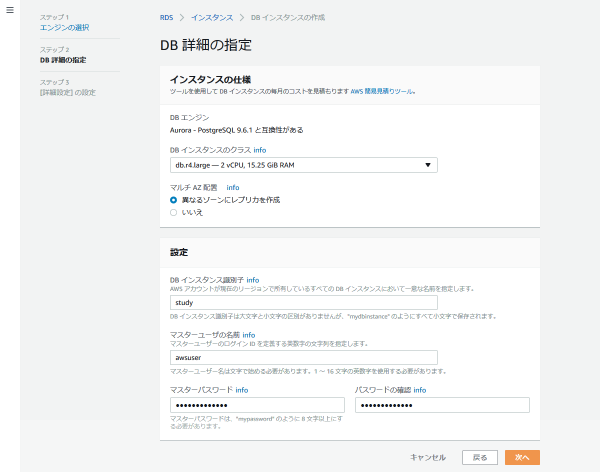
インスタンスタイプを選んで、マルチAZ配置を有効(異なるゾーンにリードレプリカを作成)にしていきましょう。
さらに「DBインスタンス識別子」を決めます。ここでは「study」としました。
クラスターを構成するマスターやリードレプリカとなるノードマシンにつけられます。
あとは管理用のログインアカウントを入力して進みます。
お次は詳細を決めていきます。
詳細設定で「DBクラスター識別子」を決めます。ここでは「mycluster」としました。
こちらは最終的にPostgreSQLクライアント・アプリから繋ぐホスト名前の接頭辞になります。
(余談ですが、クラスターを束ねる名称の入力が最初にあると思いきや詳細側にあったので少し違和感がありました。)
あとはAWSではおなじみのセキュリティグループの設定と、スナップショットなどをしていき、忘れてはならない「パフォーマンスインサイトの有効化」を選択しましょう。
そしてぽちっとな。
暫く待ちます・・・。
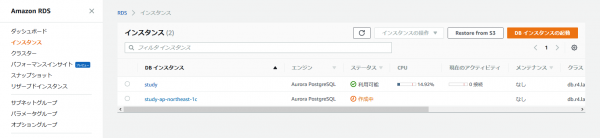
インスタンスの一覧を凝視してましたが、書き込み可能なマスターノードが生成された段階でクラスターとして利用可能になって、次に読み取り専用のレプリカノードが出来上がるようです。
できた!
正確には計っていませんが、15分位かかりました。意外と長くかかった感じです。
クラスター接続用のエンドポイントが2つ定義されています。
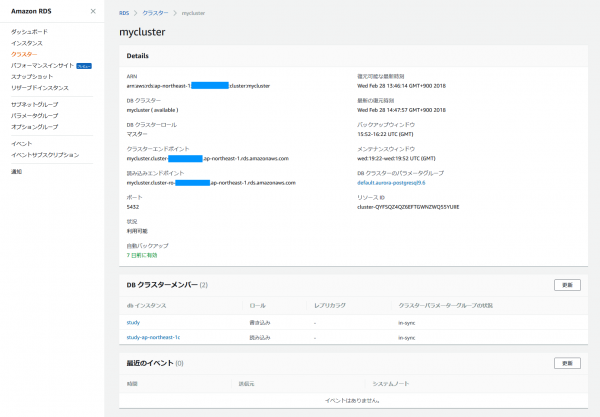
常にマスターを示すホスト名
mycluster.cluster-********.ap-northeast-1.rds.amazonaws.com
リードレプリカを示すホスト名(-roが付いてます)
mycluster.cluster-ro-********.ap-northeast-1.rds.amazonaws.com
今回はリードレプリカのインスタンスを1つしか作りませんでしたが、複数作るとDNSラウンドロビンによってその時々でいずれか1つのレプリカノードに名前解決されるそうです。
クラスター用のホスト名の解決には、Route 53サービスでDNSのCNAMEレコードをコントロールすることで実際のインスタンスノードをポイントしているみたいです。
ちなみにレプリカノードが無いと-roのホスト名もマスターと同じインスタンスノードを指し示します。
AZ構成無しだとこのパターンになると思います。
ベンチ
早速、PostgreSQLのベンチマークでおなじみ「pgbench」を使ってテストするので、まずは専用のデータベースを準備していきましょう。
手元のWindows 10マシンから繋いでみます。
C:tmp> set PGHOST=mycluster.cluster-********.ap-northeast-1.rds.amazonaws.com
C:tmp> set PGUSER=awsuser
データベースを作って、テストデータを入れます。
C:tmp> createdb mydb
C:tmp> pgbench -i -s 100 -d mydb
一先ずベンチが正常に終わることを確認しておきます。(結果は割愛)
C:tmp> pgbench -c 50 -j 50 -t 100 -d mydb
フェイルオーバーさせてみる
お次は今回の主題、データーベース側の復帰能力を確かめてみました。
システム運用中に背筋が凍る障害のひとつ、データベースダウン。恐ろしや。。。
書き込みノードで障害が起きた時を模して、ベンチマーク計測中にフェイルオーバー状態にしてみます。
ベンチの実行を開始します。結果はすべてファイルに保存しておきましょう。後から見ます。
C:tmp> pgbench -c 50 -j 50 -t 100 -d mydb > bench-log.txt 2>&1
AWSコンソールで、インスタンスを選択して「インスタンス操作」メニュー>フェイルオーバー。
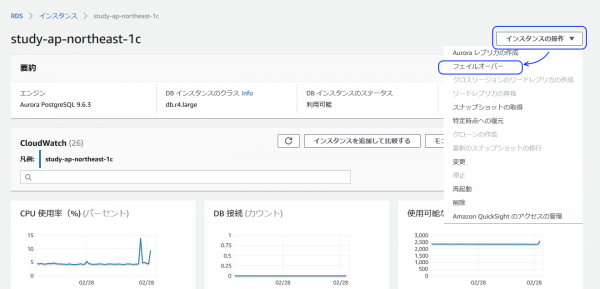
AWSコンソールのイベントログで確認すると、フェイルオーバー全体は30秒で完了していました。
公式の宣伝文句通りですね。
保存したベンチで実際に障害にあった(クエリ実行に失敗していた)期間をみると、なんと5秒でした。
その後は何事もなかったかのようにテストが続行されました。
実際にはデータベースの利用状況に大きく左右されると思いますが、
この復帰力はすげぇ。
パフォーマンスインサイト!
さて、もう1つのお楽しみ。パフォーマンスサイトでどこまで見れるか。
現在、Aurora with PostgreSQLだけに提供されているパフォーマンスインサイトをちらりと見てみました。
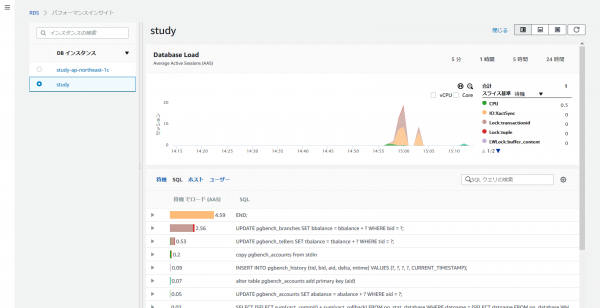
これが良い感じ。
今までだと「pg_stat_activity」拡張を使って集めていたような情報がグラフィカルにかつ見やすい。
さらに、パラメータ化クエリも実値ごとにドリルダウンする事もできて素晴らしい。
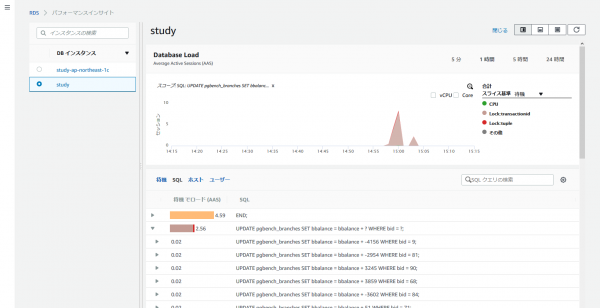
わざわざ運用中にパフォーマンス調査用の特別な設定をしなくてもクエリコストが見えるのは、開発する身としては今後のチューニングや今ボトルネックになっている部分を即座に確認できて伝家の宝刀並みの頼もしさを感じました。
おわりがき
技術的なところ
AWSドキュメントのベストプラクティスにJDBCの設定についてと、OSレベルのキープアライブ設定についても書かれて
いるので、本格的に使う前にはセオリー通りの内容について理解を深める必要がありそうです。
何といっても参照系のクエリについてはリードレプリカ側のエンドポイントに接続して処理を分散できる仕組みを導入しないことには旨み半分ですね。待機系とするにはもったいない。
アプリケーションの実装によっては、DBドライバーの機能に頼らずに自前で参照のみと更新を含むトランザクションを振り分けるようなフレームワークの検討が必要なあたりは、既存のDBクラスタリングと変わらないですね。
複数のレプリカノードを効率よく使うにはDNSラウンドロビンが効く必要があるので、接続プーリングと排他的な一面があります。これは再接続コストとの天秤なので悩ましいですね…。
感想
30秒以内の自動フェイルオーバー、リードレプリカの増設、ディスクの自動拡張、定期バックアップ、パフォーマンス監視等々…これらをマウスぽちぽちで直ぐに環境を調達できるなんて、改めて良い時代です。しかもコーヒー1本分。
小規模開発や単純なデータストアだけで利用するならコスト高ですが、運用に掛かる人的コストや障害・復旧対策までトータルに考えるなら十分に検討価値があると感じました。
それではまた!
資料
より技術的な内容に興味がある方は以下の記事解説があるので参考にされたい。
・Amazon Auroraの先進性を誰も解説してくれないから解説する – kumagi氏
https://qiita.com/kumagi/items/67f9ac0fb4e6f70c056d
・Amazon Aurora PostgreSQL – AWSサミット PDF資料
https://d1.awsstatic.com/events/jp/2017/summit/slide/D2T1-3.pdf
・【AWS Database Blog】Aurora ストレージエンジンのご紹介
http://aws.typepad.com/sajp/2017/02/introducing-the-aurora-storage-engine.html
・【AWSドキュメント】Amazon Aurora PostgreSQL を使用する際のベストプラクティス
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/AuroraPostgreSQL.BestPractices.html


